Tooling & Productivity
Gobbler
30 January 2026
Gobbler is a document-to-data processing platform that transforms files from multiple formats (PDFs, emails, Word, Excel, CSV) into structured data objects. It enables non-technical users to analyse patterns across these data objects using an integrated AI agent.
Summary
Gobbler is a AI data analysis companion designed to help public officers make sense of messy, semi-structured data, such as complaints, cases, surveys, and free-text submissions in a transparent and responsible way.
Instead of producing “answers” like a chatbot, the system guides users through a schema-first, analysis-driven workflow:
Documents are parsed and extracted into structured data objects
Users define (or confirm) the fields that matter
An AI agent plans and executes real analytical methods (e.g. clustering) in a sandboxed Python environment
The agent’s planning steps and code are visible, so users can understand the methodology, assumptions, and limitations
The product is intentionally positioned as an augmentation tool, not a replacement for analytical thinking. It is optimised for sense-making and early-stage analysis, helping officers build intuition, surface patterns, and ask better questions — rather than generate audit-ready reports.
Problem Statement
Public officers want to use data to inform decisions, but time-to-first-insight is too long, leaving little space for actual analysis and judgment.
In practice:
A large share of time is spent preparing data before any insight can be drawn
Studies consistently show ~60–80% of analysis time goes into data preparation, not analysis
Many officers lack confidence in analytical workflows, making exploration slow and error-prone
Generative AI lowers the barrier to getting answers, but introduces new risks:
Users may trust outputs without understanding the data or method
Important assumptions and limitations are hidden
Data literacy does not improve — dependency increases
The result is a double bind:
Too much time spent getting to first insight
Too little understanding of how insights are produced
The opportunity is to shorten time-to-first-insight while strengthening data literacy, so officers can spend more time analysing, questioning, and applying judgment — not just preparing data or trusting black-box answers.
Our Solution
A three-layer, AI-augmented approach that reduces time-to-first-insight while strengthening data literacy.
1. Schema-First Foundation
Users define or confirm via auto-detection the fields that matter before analysis begins. This grounds the work in shared definitions, reduces ambiguity, and ensures users retain ownership of what the data represents.
2. AI-Augmented Analysis
An AI agent plans and executes real analytical methods (e.g. clustering) in a sandboxed Python environment. The agent’s plans and code are visible, helping users understand the methodology rather than blindly trusting outputs.
3. Sense-Making, Not Final Answers
The tool is explicitly positioned for early-stage exploration:
Pattern discovery
Hypothesis generation
Gut-sense checks
It supports human judgment at the front of the analysis process, not report-grade conclusions, reinforcing that AI augments thinking rather than replaces it.
Initial User Feedback
We demoed an early working prototype to public officers to showcase the end-to-end flow: from schema setup, data extraction, to AI-augmented analysis. These sessions primarily informs how users reasoned with the tool, rather than to validate individual features.
Key feedback and observations
Users do not know the difference between a RAG solution and our proposed solution
Schema setup can be tedious
Hallucination risk increases when users don’t understand the data
Concerns from team leads that users don’t internalise the analysis process and they will over time, trust outputs blindly
Intent is easily lost if the AI “feels too capable”
Design responses
Add schema auto-detection to ease setup
Show agent planning and code to surface thinking, not hide it
Encourage engagement with data wrangling as part of sense-making
Reinforce that AI does not know which data points matter without guidance
Reframe the tool as an assistant, not an analyst
Clear use-case boundary
Strong fit: market sensing, complaints, surveys, case analysis
Weak fit: heavy quantitative analysis, compliance, definitive reporting
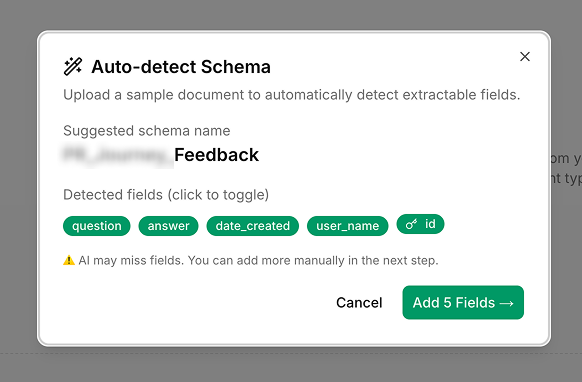
Auto-detection of schema eases setup action by users
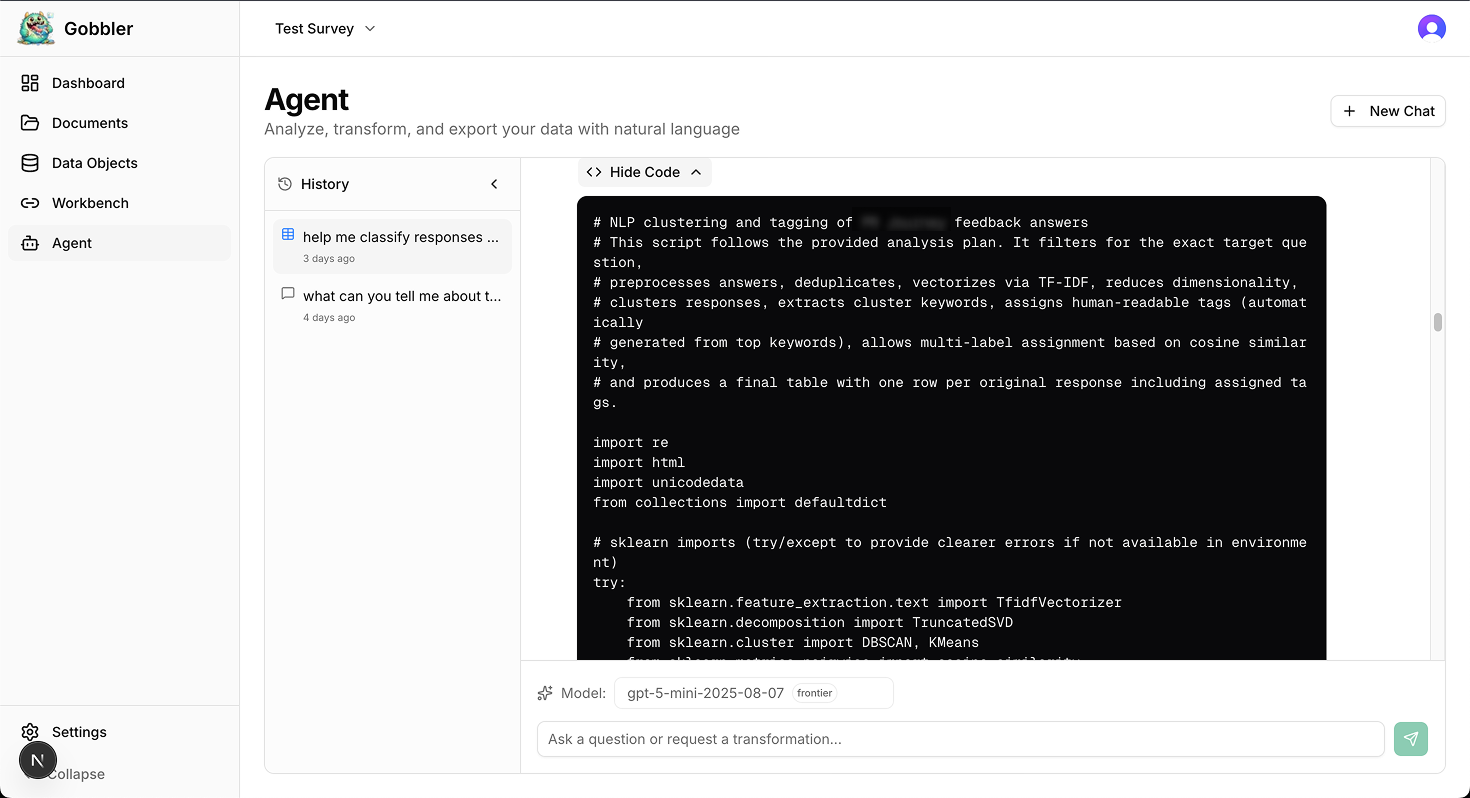
Gobbler writes code and execute them in a sandbox to analyse your extracted data objects.
Opportunity, Velocity, and Traction
Opportunity
As mentioned in our problem statement, public officers want to use data to inform decisions, but time-to-first-insight is too long, leaving little space for actual analysis and judgment.
The Problem: Teams spend more time "cleaning" data, copy-pasting and manual entry, than actually running analysis to generate the insights.
Who it affects: Policy and operations teams who need to make sense of hundreds of different documents quickly.
The Risk: When data is handled manually, it’s slow and prone to human error. Important insights that could improve public services are often missed because the "paperwork" is too overwhelming to analyse.
Why it matters: By automating the messy work of data preparation, we allow public officers to focus on high-value analysis and faster service delivery for citizens.
Velocity
We have moved from simple document storage to a system that "understands" and organises information into a format ready for AI analysis.
Structured Extraction: You can upload a batch of varied documents (e.g., a PDF claim and a Word email), setup or auto-detect the schema and Gobbler will automatically extract matching data points into a single, reconciled table.
Cross-File Reconciliation: We built a feature that identifies when two different files refer to the same ID, person or case, merging them into one "source of truth."
AI-Ready Output: Gobbler then outputs clean data that can be plugged directly into professional analysis tools or scripts.
AI-Agent Analysis: More than just RAG, the AI agent will plan, then write python codes that's executed in a sandbox to analyse the data according to the user's prompts.
Traction
Gobbler was tested with product managers who need to analyse product feedback from various channels. We have also demonstrated and interviewed agency data teams on the usefulness of such tools when their users have light data analysis needs.
Prototyping: Team members dogfood the prototype by running analysis on large amounts of survey responses (> 3k entries). Interviewed 3 data teams across MDDI, MCCY, and NYC.
Time Saved: It takes less than an hour to analyse about 3000 entries of survey responses where it usually takes up to 4 if we were to manually clean the data and write scripts to analyze it, saving us 3 hours.
Accuracy: The prototype is fairly accurate in terms of parsing, extracting and reconciling of data points across multi-format files however the agentic analysis of data could use more evals and testing to assess its accuracy.
User Feedback: "This tool definitely has the potential to help some of my business users sense-make their data in a self-service way but we need to make it clear that it may not be accurate enough for reporting purposes" — A senior manager in an agency data team
What’s Next?
Immediate (Next 2 weeks):
Continue to gather additional user feedback from demo day and user testing
Short-term (1-2 months):
Launch alpha version hosted on GCC and expand user testing
Comprehensive evals for AI analysis companion
Improve parsing and data extraction speed using concurrent workers
Data visualisation agent tools
Long-term (3-6 months):
Gobbler-as-a-middleware use case exploration
Explore integration with government digital services ecosystem
Team Members
Core Members:
Benedict Chiam, MCCY
Anjana Balakrishnan, MCCY
Special Thanks:
Petrina Yeow, OGP
Tracy Hung, MDDI
Zhong Liang Ou Yang, OGP